机器之心编辑部
是时候抛弃 tokenization 了?
ChatGPT 等对话 AI 的出现让人们习惯了这样一件事情:输入一段文本、代码或一张图片,对话机器人就能给出你想要的答案。但在这种简单的交互方式背后,AI 模型要进行非常复杂的数据处理和运算,tokenization 就是比较常见的一种。
 (资料图)
(资料图)
在自然语言处理领域,tokenization 指的是将文本输入分割成更小的单元,称为「token」。这些 token 可以是词、子词或字符,取决于具体的分词策略和任务需求。例如,如果对句子「我喜欢吃苹果」执行 tokenization 操作,我们将得到一串 token 序列:[\"我\", \"喜欢\", \"吃\", \"苹果\"]。有人将 tokenization 翻译成「分词」,但也有人认为这种翻译会引起误导,毕竟分割后的 token 未必是我们日常所理解的「词」。
图源:https://towardsdatascience.com/dynamic-word-tokenization-with-regex-tokenizer-801ae839d1cd
Tokenization 的目的是将输入数据转换成计算机可以处理的形式,并为后续的模型训练和分析提供一种结构化的表示方式。这种方式为深度学习研究带来了便利,但同时也带来了很多麻烦。前段时间刚加入 OpenAI 的 Andrej Karpathy 指出了其中几种。
首先,Karpathy 认为,Tokenization 引入了复杂性:通过使用 tokenization,语言模型并不是完全的端到端模型。它需要一个独立的阶段进行 tokenization,该阶段有自己的训练和推理过程,并需要额外的库。这增加了引入其他模态数据的复杂性。
此外,tokenization 还会在某些场景下让模型变得很容易出错,比如在使用文本补全 API 时,如果你的 prompt 以空格结尾,你得到的结果可能大相径庭。
图源:https://blog.scottlogic.com/2021/08/31/a-primer-on-the-openai-api-1.html
再比如,因为 tokenization 的存在,强大的 ChatGPT 竟然不会将单词反过来写(以下测试结果来自 GPT 3.5)。
这样的例子可能还有很多。Karpathy 认为,要解决这些问题,我们首先要抛弃 tokenization。
Meta AI 发表的一篇新论文探讨了这个问题。具体来说,他们提出了一种名为「 MEGABYTE」的多尺度解码器架构,可以对超过一百万字节的序列进行端到端可微建模。
论文链接:https://arxiv.org/pdf/2305.07185.pdf
重要的是,该论文展现出了抛弃 tokenization 的可行性,被 Karpathy 评价为「很有前途(Promising)」。
以下是论文的详细信息。
论文概览
在 机器学习的文章 中讲过,机器学习之所以看上去可以解决很多复杂的问题,是因为它把这些问题都转化为了数学问题。
而 NLP 也是相同的思路,文本都是一些「非结构化数据」,我们需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题了,而分词就是转化的第一步。
由于自注意力机制和大型前馈网络的成本都比较高,大型 transformer 解码器 (LLM) 通常只使用数千个上下文 token。这严重限制了可以应用 LLM 的任务集。
基于此,来自 Meta AI 的研究者提出了一种对长字节序列进行建模的新方法 ——MEGABYTE。该方法将字节序列分割成固定大小的 patch,和 token 类似。
MEGABYTE 模型由三部分组成:
patch 嵌入器,它通过无损地连接每个字节的嵌入来简单地编码 patch;
全局模块 —— 带有输入和输出 patch 表征的大型自回归 transformer;
局部模块 —— 一个小型自回归模型,可预测 patch 中的字节。
至关重要的是,该研究发现对许多任务来说,大多数字节都相对容易预测(例如,完成给定前几个字符的单词),这意味着没有必要对每个字节都使用大型神经网络,而是可以使用小得多的模型进行 intra-patch 建模。
MEGABYTE 架构对长序列建模的 Transformer 进行了三项主要改进:
1. sub-quadratic 自注意力 。大多数关于长序列模型的工作都集中在减少自注意力的二次成本上。通过将长序列分解为两个较短的序列和最佳 patch 大小,MEGABYTE 将自注意力机制的成本降低到,即使是长序列也能易于处理。
2. per-patch 前馈层 。在 GPT-3 等超大模型中,超过 98% 的 FLOPS 用于计算 position-wise 前馈层。MEGABYTE 通过给 per-patch(而不是 per-position)使用大型前馈层,在相同的成本下实现了更大、更具表现力的模型。在 patch 大小为 P 的情况下,基线 transformer 将使用具有 m 个参数的相同前馈层 P 次,而 MEGABYTE 仅需以相同的成本使用具有 mP 个参数的层一次。
3. 并行解码 。transformer 必须在生成期间串行执行所有计算,因为每个时间步的输入是前一个时间步的输出。通过并行生成 patch 的表征,MEGABYTE 在生成过程中实现了更大的并行性。例如,具有 1.5B 参数的 MEGABYTE 模型生成序列的速度比标准的 350M 参数 transformer 快 40%,同时在使用相同的计算进行训练时还改善了困惑度(perplexity)。
总的来说,MEGABYTE 让我们能够以相同的计算预算训练更大、性能更好的模型,将能够处理非常长的序列,并提高部署期间的生成速度。
MEGABYTE 还与现有的自回归模型形成鲜明对比,后者通常使用某种形式的 tokenization,其中字节序列被映射成更大的离散 token(Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021) 。tokenization 使预处理、多模态建模和迁移到新领域变得复杂,同时隐藏了模型中有用的结构。这意味着大多数 SOTA 模型并不是真正的端到端模型。最广泛使用的 tokenization 方法需要使用特定于语言的启发式方法(Radford et al., 2019)或丢失信息(Ramesh et al., 2021)。因此,用高效和高性能的字节模型代替 tokenization 将具有许多优势。
该研究对 MEGABYTE 和一些强大的基线模型进行了实验。实验结果表明,MEGABYTE 在长上下文语言建模上的性能可与子词模型媲美,并在 ImageNet 上实现了 SOTA 的密度估计困惑度,并允许从原始音频文件进行音频建模。这些实验结果证明了大规模无 tokenization 自回归序列建模的可行性。
MEGABYTE 主要组成部分
patch 嵌入器
全局模块
全局模块是一个 decoder-only 架构的 P・D_G 维 transformer 模型,它在 k 个 patch 序列上进行操作。全局模块结合自注意力机制和因果掩码来捕获 patch 之间的依赖性。全局模块输入 k 个 patch 序列的表示,并通过对先前 patch 执行自注意力来输出更新的表示。
最终全局模块的输出包含 P・D_G 维的 K 个 patch 表示。对于其中的每一个,研究者将它们重塑维长度为 P、维度为 D_G 的序列,其中位置 p 使用维度 p・D_G to (p + 1)・D_G。然后将每个位置映射到具有矩阵的局部模块维度,其中 D_L 为局部模块维度。接着将这些与大小为 D_L 的字节嵌入相结合,用于下一个的 token。
局部字节嵌入通过可训练的局部填充嵌入(E^local-pad ∈ R^DL)偏移 1,从而允许在 path 中进行自回归建模。最终得到张量
局部模块
效率分析
训练效率
在缩放序列长度和模型大小时,研究者分析了不同架构的成本。如下图 3 所示,MEGABYTE 架构在各种模型大小和序列长度上使用的 FLOPS 少于同等大小的 transformer 和线性 transformer,允许相同的计算成本下使用更大的模型。
生成效率
考虑这样一个 MEGABYTE 模型,它在全局模型中有 L_global 层,在局部模块中有 L_local 层,patch 大小为 P,并与具有 L_local + L_global 层的 transformer 架构进行比较。用 MEGABYTE 生成每个 patch 需要一个 O (L_global + P・L_local) 串行操作序列。当 L_global ≥ L_local(全局模块的层多于局部模块)时,MEGABYTE 可以将推理成本降低近 P 倍。
实验结果
语言建模
研究者在强调长程依赖的 5 个不同数据集上分别评估了 MEGABYTE 的语言建模功能,它们是 Project Gutenberg (PG-19)、Books、Stories、arXiv 和 Code。结果如下表 7 所示,MEGABYTE 在所有数据集上的表现始终优于基线 transformer 和 PerceiverAR 。
研究者还扩展了在 PG-19 上的训练数据,结果如下表 8 所示,MEGABYTE 显著优于其他字节模型,并可与子词(subword)上训练的 SOTA 模型相媲美。
图像建模
研究者在 ImageNet 64x64 数据集上训练了一个大型 MEGABYTE 模型,其中全局和局部模块的参数分别为 2.7B 和 350M,并有 1.4T token。他们估计,训练该模型所用时间少于「Hawthorne et al., 2022」论文中复现最佳 PerceiverAR 模型所需 GPU 小时数的一半。如上表 8 所示,MEGABYTE 与 PerceiverAR 的 SOTA 性能相当的同时,仅用了后者一半的计算量。
研究者比较了三种 transformer 变体,即 vanilla、PerceiverAR 和 MEGABYTE,以测试在越来越大图像分辨率上长序列的可扩展性。结果如下表 5 所示,在这一计算控制设置下,MEGABYTE 在所有分辨率上均优于基线模型。
下表 14 总结了每个基线模型使用的精确设置,包括上下文长度和 latent 数量。
音频建模
音频兼具文本的序列结构和图像的连续属性,这对 MEGABYTE 而言是一个有趣的应用。本文模型获得 3.477 的 bpb,明显低于 perceiverAR(3.543)和 vanilla transformer 模型(3.567)。更多消融结果详见下表 10。
更多技术细节和实验结果请参阅原论文。
标签:
上一篇 : 我国启动首个5G异网漫游商用模式 四大运营商共建共享-当前视讯
下一篇 : 最后一页
最新推荐
近日,乐事薯片推出了一个小家电——洗手指机。这对薯片爱好者来说是十分实用的小物件,可以做到秒开吃...

律师兼任调解员,不打官司也能化解纠纷,代理调解受指派的公益性案件还免费。这是兵团第十师北屯市探索...

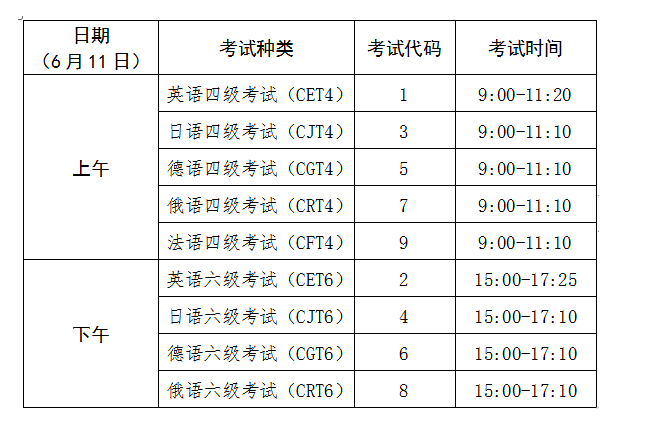
根据教育部教育考试院统一安排,2022年上半年全国大学英语四、六级口语考试将于5月21日-22日举行,笔试...
学生代购的“苦”与“乐” “你问的这个产品现在做促销活动,买一件包邮,还送小样和面膜……”...

11月11日大连市新冠肺炎疫情防控总指挥部发布,11月10日0时至24时,大连市新增21例本土新冠肺炎确诊...
纤维素制成闪光材料无毒可降解 或彻底改变化妆品行业 科技日报北京11月11日电 (实习记者张...
海洋中或堆积了2 8万吨新冠废物 科技日报北京11月11日电 (记者刘霞)据美国趣味科学网站10日报...
开屏广告又现新花招,换个马甲就重来? ■ 来论 据媒体报道,“双十一”期间,一些App的开屏...
对不合理教师资格认定标准,该全面清理了 ■ 来论 针对网友留言反映的“糖尿病无法通过教师...
虚假宣传、以次充好、售卖临期产品不提示直播间商家“放水”让消费者闹心 关注“双11” 今年...
“扫码抽手机”实则是广告 快递单能“领红包”面单广告是谁发的? “双11”之际,消费者被商...
中新网11月12日电 据北京市疾病预防控制中心微信公众号消息,2021年11月10日北京市接报1例在京存在...
(抗击新冠肺炎)辽宁大连本轮疫情病毒为德尔塔变异株 24个区域划定为中风险地区 中新社大连11月1...
中新网西安11月11日电 (梅镱泷 杨起超)记者11日从西安市鄠邑区秦保局获悉,太平国有生态林场架设...
(抗击新冠肺炎)成都停业整顿56家零售药店 买感冒药需提供身份证 中新网成都11月11日电 (记者 ...
中新网大连11月11日电 (记者 杨毅) 11月11日,大连市政府秘书长衣庆焘在大连疫情防控新闻发布会...
新华社杭州11月11日电(记者冯源)在商周时期,如今的浙江中西部活跃着一个名为“姑蔑”的族群,但是...
中新网大连11月11日电 (记者 杨毅)11月11日,大连市政府秘书长衣庆焘在大连疫情防控工作新闻发布...
中新网大连11月11日电 (记者 杨毅)11月11日,大连市政府秘书长衣庆焘在大连疫情防控工作新闻发布...
中新网昆明11月11日电(记者 缪超)云南“最美政法干警”发布仪式11日在昆明举行。会上,授予昆明市...
(抗击新冠肺炎)甘肃凝聚“她力量”:互助抗疫,女人更懂女人心 中新网兰州11月11日电 (记者 徐...
中新网兰州11月11日电 (史静静)在甘肃金川公司,27年来葛小海始终在生产一线,他参与的“渣罐车制...
中新网乌鲁木齐11月11日电 (王小军 罗宣政 廖超)11月11日,一批来自浙江嘉兴的爱心物资,跨越...
中新网兰州11月11日电 (邬凡 朱学成)11月10日5时30分,位于敦煌车站旁的敦煌综合工区,钢轨探伤车...
中新网重庆11月11日电 (梁钦卿)“我今年上小学三年级了,我不怕疼,打疫苗是为了抵抗新冠病毒。”1...
中新网绵阳11月11日电 (岳波 李远梅)四川绵阳警方11日通报称,一男子酒后无聊多次报警称自己的...
中新网11月11日电 据中国民航局网站消息,11月11日,民航局再发熔断指令,对德国汉莎航空公司LH728...
中新网成都11月11日电 题:疫情中轮椅上的“逆行者”:想为大家做力所能及的事 作者 祝欢 ...
中新网上海11月11日电 (记者 李姝徵)上海警方11日召开发布会披露,在近期“砺剑”行动中破获了一...
中新网太原11月11日电 (记者 李庭耀)记者11日从山西省政府新闻办举行的新闻发布会上获悉,山西推...
中新网乌鲁木齐11月11日电 (刘雨珊 牛雨萌 艾尼)11日,记者从新疆水产科研所获悉,新疆博湖县将...
中新网大连11月11日电 (记者 杨毅)大连市新冠肺炎疫情防控总指挥部 11日发布公告,大连市将庄河...
中新网西安11月11日电 (记者 党田野)身穿白色“礼服”,摇晃着酒杯,时不时浅酌一口啤酒,然后与...
11月11日大连市新冠肺炎疫情防控总指挥部发布,按照国务院应对新冠肺炎疫情联防联控机制关于科学划...
中新网南京11月11日电 题:这个“双十一”南京的猪都“脱单”了 其实还有更让人嫉妒的…… ...
中新网呼伦贝尔11月11日电 (记者 张林虎)11日,记者从内蒙古自治区呼伦贝尔市公安局获悉,该局将...
中新网广州11月11日电 (记者 程景伟)“寻味帅府邂逅甜蜜——2021年帅府之夜”暨“海外拾珠——孙...
中新网徐州11月11日电 题:江苏徐州“家门口车管所”便民服务驶入“高速路” 作者 朱志庚 ...
中新网重庆11月11日电 (梁钦卿)为加强秋冬季空气污染应对,重庆市生态环境局11日发出2021年第九次...
新华社重庆11月11日电 题:深藏功名三十载 化作春蚕报乡亲——一名抗美援朝老兵的人生选择 新...
中新网益阳11月11日电 (王鹏 王庆庆)爱花本是修身养性、陶冶情操之事,湖南益阳市桃江县桃花江镇...
中新网成都11月11日电 题:成都25位民辅警的“封闭”生活:有人“转行”送外卖 有人变身“仓鼠管...
中新网南京11月11日电 (徐珊珊)江苏省教育厅体育卫生与艺术教育处处长张鲤鲤11日在南京表示,到202...
中新网成都11月11日电 (记者 吕杨)成都市公园城市建设管理局11日正式发布公园城市银杏观叶指数,...

中新网南京11月11日电 (徐珊珊)11日,江苏省教育厅召开新闻发布会,发布2020年江苏省学生体质健康...

中新网宜昌11月11日电 (江雅丽 董晓斌)17年前,四川广安一夫妇的6岁儿子被人拐走,夫妻俩寻找多年...

中新网宁德11月11日电 (林榕生)福建宁德市柘荣县应对新型冠状病毒感染肺炎疫情工作领导小组(指挥部...

11月11日,内蒙古额济纳旗新冠肺炎防控工作指挥部发布《关于调整额济纳旗达来呼布镇风险等级的公告...

(抗击新冠肺炎)内蒙古现有本土确诊病例32例 伊金霍洛旗确诊病例清零 中新网呼和浩特11月11日电...

中新网呼和浩特11月11日电 (记者 张林虎)11日,记者从内蒙古自治区通辽市相关部门获悉,从10日下...


成都抗疫的外籍志愿者:愿为城市“康复”贡献力量
Copyright © 2015-2022 亚太律师网版权所有 备案号:沪ICP备2020036824号-11 联系邮箱: 562 66 29@qq.com
